
– Project Status: Active
Objective
To develop a web based platform that gives personalized recommendations for travel destinations and activities based on user preferences. The recommendations will be accompanied with a list of directly comparable features pertaining to the suggested destinations, such that the user(s) can delve deeper and emerge with a satisfied choice.
To this end, a bottom-up solution algorithm is adopted:
- At the top level, a list of countries are considered
- Each country contains a list of travel destinations
- Each destination contains a list of Points Of Interest (POI)
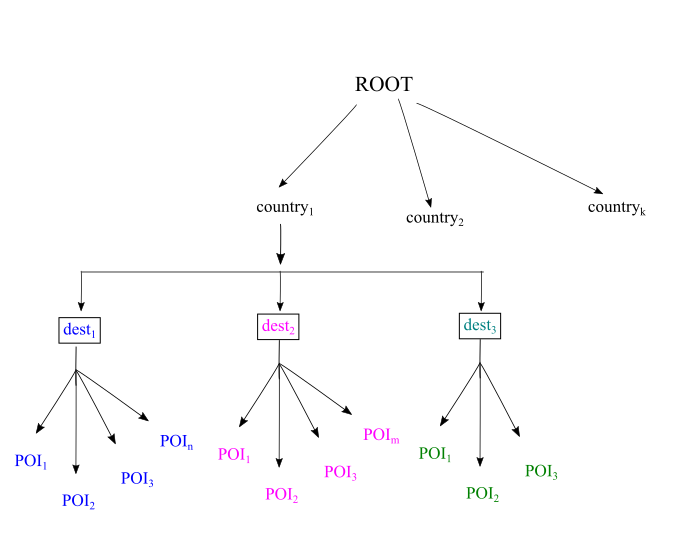
We will predict the scores of the POIs based on user profile. Next, these scores will be aggregated to give a net score for all travel destinations. The top N destinations will be recommended to the user. The similar steps can we followed, to suggest countries that a user may be interested in.
This is an end-to-end data science project, spanning all stages such as data collection, data exploration, data cleaning, feature extraction, model development, model validation and data visualization.
These stages are briefly summarized in the following.
Data collection
The objective is to build a dataset containing information of tourist destinations around the globe. After browsing through several travel sites, I decided to collect data from Triposo and TripAdvisor, since they offer comprehensive details and user reviews regarding tourist attractions.
Triposo
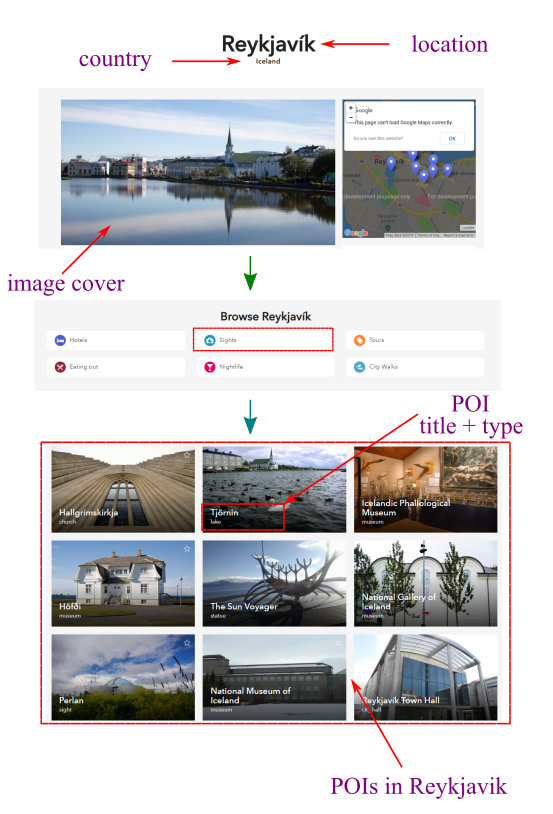
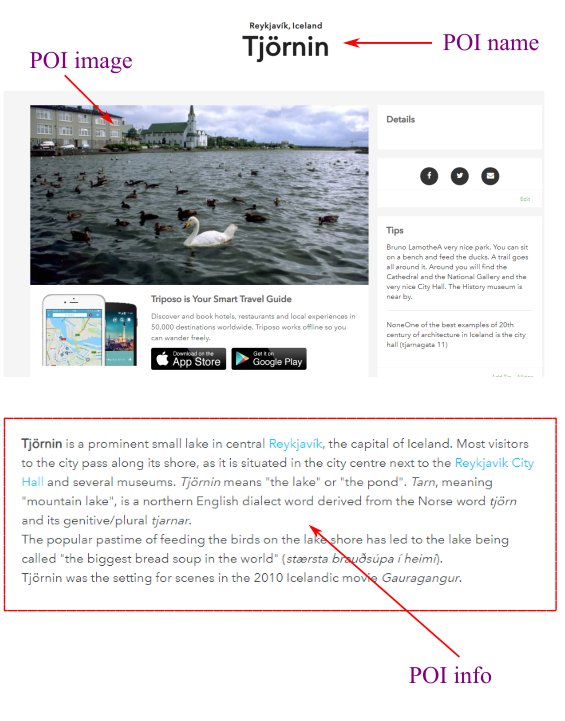
Details of 250k Points Of Interest (POI) are collected from Triposo. The following attributes of each POI are stored:
- Title: Name of POI
- Location: Which location/city the POI belongs to
- Country: country –> location –> POI
- POI type: e.g. museum, lake, mountain, church
- POI info: a short description of the POI
- POI image: cover image of the POI
- POI rank: Index of the POI withing the POI list for a location
This jupyter notebook contains details of the data collection steps:
- Make a list of countries to include in the dataset
- For each country find the urls of travel destinations
- For each travel destination extract details of POIs
TripAdvisor
The collaborative filtering mechanism utilizes underlying user-item interaction for making recommendations. In this case, the users and items are travelers and tourist attractions respectively. To build a user-item matrix, information from the TripAdvisor are scraped. The APIFY TripAdvisor scraper offers a ready-made and fast crawler to get the relevant information. Using APIFY, reviews of many tourist attractions in south-east Asia and Europe are extracted. Two separate tables are created: TA_attractions and TA_reviews.
TA_attractions
The table TA_attractions stores the following information for each attraction:
- location_id: unique id for an attraction
- name: name of the attraction
- latitude and longitude: geographical coordinates
- description: a short description of the attraction
- web_url: url of the page
- subcategory: type of attraction
- subtype: more refined class of subcategory
- num_reviews: total number of reviews for an attraction
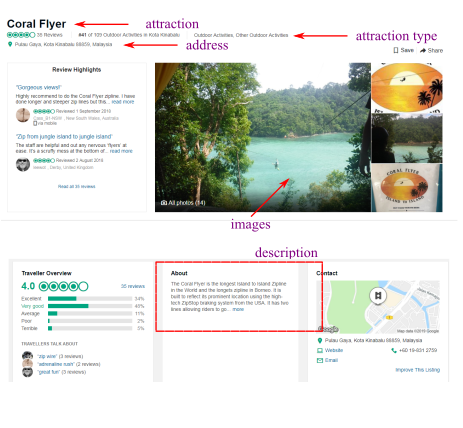
TA_reviews
The reviews tables stores all scraped reviews with the following fields:
- user: TA user name of the reviewer
- location_id: the unique id of the rated location
- location_name: name of the location
- rating: given rating for the attraction (1 to 5 stars)
- comment: the text content of the review
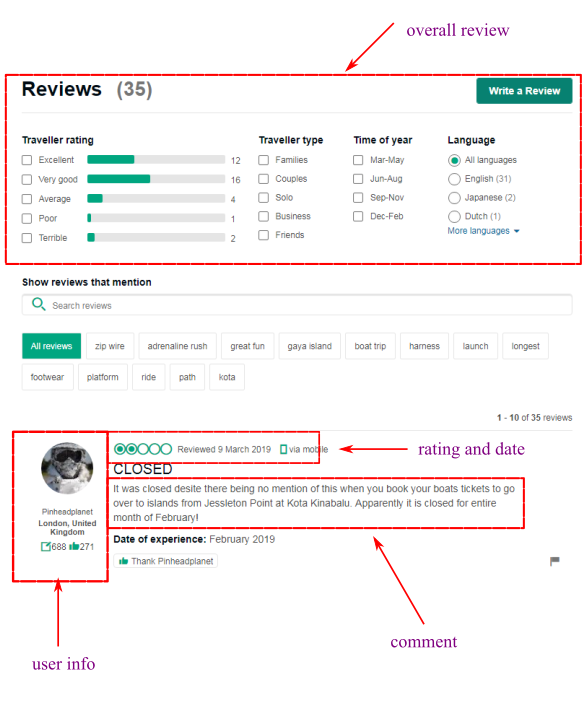
Create POI database
The extracted data is finally stored in MySQL database. The relationship schema is shown below:
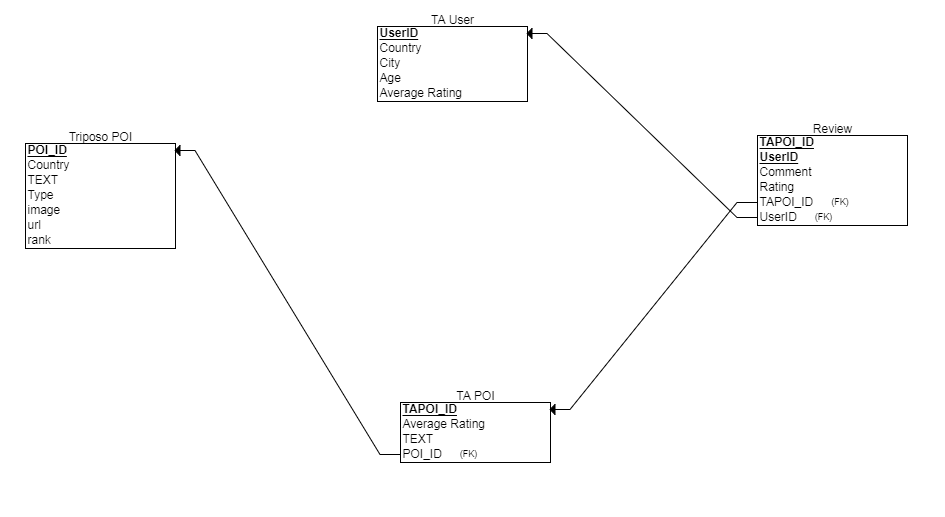
– to be updated: TA User table not implemented
Data exploration
The notebook for data exploration can be accessed here.
Triposo EDA
Information regarding 230k+ travel attractions (POI) are extracted. A sample of 5 POIs is shown below:

Each POI is attributed to a POI type e.g. lake, mountain and sight. The top 15 POI type with respect to their frequency are:
| POI Type | Frequency |
|---|---|
| sight | 46675 |
| museum | 38720 |
| park | 28234 |
| church | 19405 |
| mountain | 8556 |
| memorial | 8493 |
| theater | 6235 |
| bridge | 5972 |
| city hall | 5286 |
| castle | 5235 |
| library | 5209 |
| temple | 3863 |
| lake | 3008 |
| tower | 2592 |
| university | 2533 |
For each POI, a short explanatory description is scraped. The word count distribution of the descriptions are:
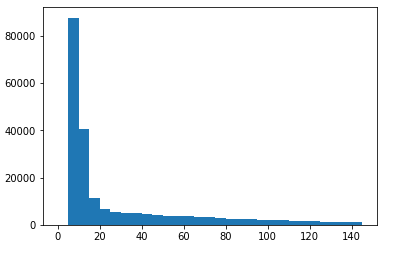
Histogram plot for number of words in text description of POIs
Cluster analysis is next performed to identify patterns among the POIs. To this end, the TF-iDF features computed from the POI text descriptions are used. To find the optimum number of clusters, the elbow method is adopted.
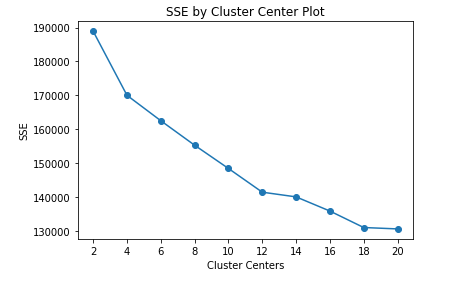
Subsequently, POIs are grouped into 12 clusters. The most frequent words in the top 4 clusters are shown in the following.
Cluster 1

Cluster 2
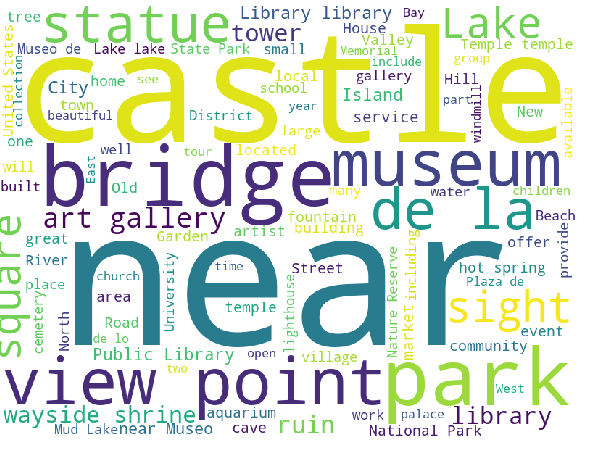
Cluster 3

Cluster 4
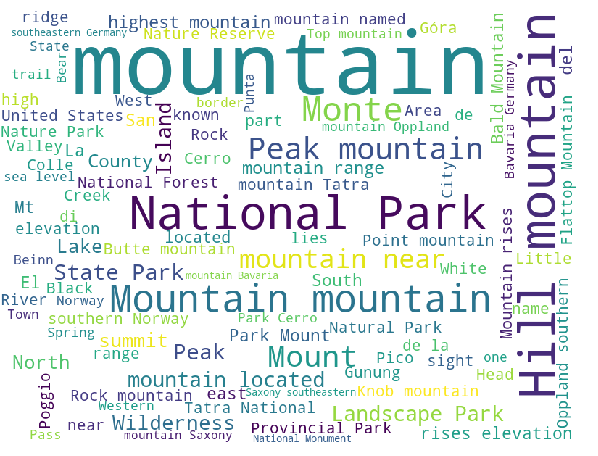
Evidently, each cluster captures different POI types. For example, in cluster 1 and 2, the dominant POI types are waterfall and castle respectively.
TripAdvisor (TA)
The purpose of scraping information from TripAdvisor is to create user-attraction matrix. It is thus important to have multiple reviews from each user in the dataset. A histogram plot for number of reviews per user is shown below:
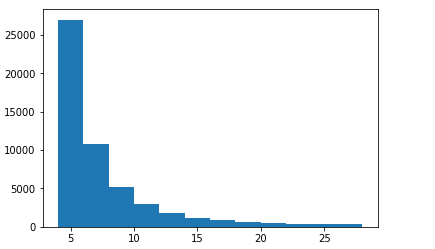
As observed, 53k+ users have at least 5 reviews. A total of 436k+ reviews are considered from these users.
Sample from TA_reviews table
Reviews from a specific user
The rating distribution is next explored. Each review rates an attraction from 1 to 5. The histogram for rating distribution is shown below:
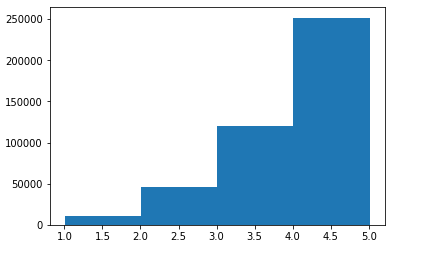
A non-uniform rating distribution is apparent from the above plot. The average and standard deviation is computed to be 4.37 and 0.89 respectively.
Data cleaning
Although the information extracted from Triposo and TripAdvisor are well structured the most part, a few issues needed to be fixed before model development:
- POIs (Triposo) for which the description has less than 4 words are dropped
- For POI description leading and trailing ‘\n’ character is removed
- Reviews from users (TripAdvisor) with less 5 reviews are dropped
- Attractions (tripAdvisor) with less than 5 reviews are removed
Feature extraction
TF-iDF
After data cleaning, a total of 230625 POIs are considered for further analyses. For each of these POIs, a 5000 dimensional feature vector is computed using TF-iDF approach. The TF-iDF matrix shape is thus (230625, 5000). TF-iDF (term frequency-inverse document frequency) is a numerical statistic that is intended to reflect how important a word is to a document. Inverse document frequency term is used to bring down importance of words that appear in many documents.
Universal Sentence Encoder
The Universal Sentence Encoder (by Google) converts any sentence into a meaningful vector.
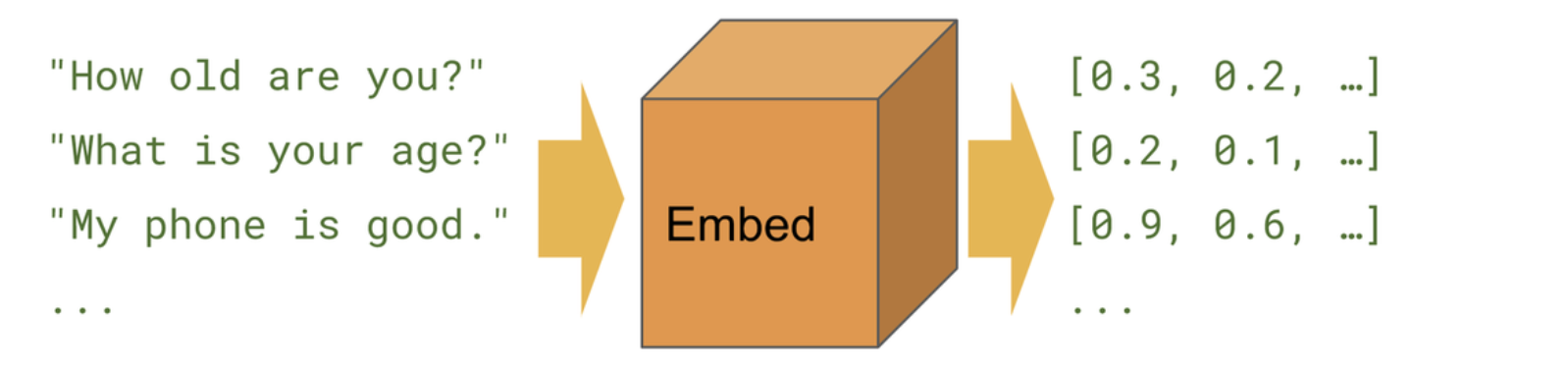
The sentence encoder is built based on the Deep Average Network (DAN) architecture. It is pre-trained on a large corpus and can be used in a variety of tasks such as sentimental analysis, classification and so on. POI descriptions from Triposo are passed through the universal sentence encoder network to get a 512-dimensional vector representation for each POI. Note that, these 512 dimensional vectors are able to capture the underlying context sensitive semantic information, which is lacking in simple count based TF-iDF method.
Image features
POIs for which a cover image is available, additional image based feature can be extracted using a pre-trained convNet architecture such as ResNet, Inception Network or EfficientNet. This step is under progress.
User-attraction interaction matrix
The collaborative filtering mechanism leverages information from the item-attraction matrix. This interaction matrix can be created by joining the TA_reviews and TA_attractions table. (to be completed soon …)
Recommender system
Content-based recommender system
The notebook for developing the content-based recommender system is summarized here. At the outset, the user will be presented with a list of POIs, along with their description and image. The user will next be requested to rate these POIs. A vector representation of the user profile will be computed based on the ratings.
User inputs





Scoring
Once the user profile vector is obtained, the score of all other POIs are computed based on cosine similarity. Next, POI scores are combined to get a net score for each travel destination:
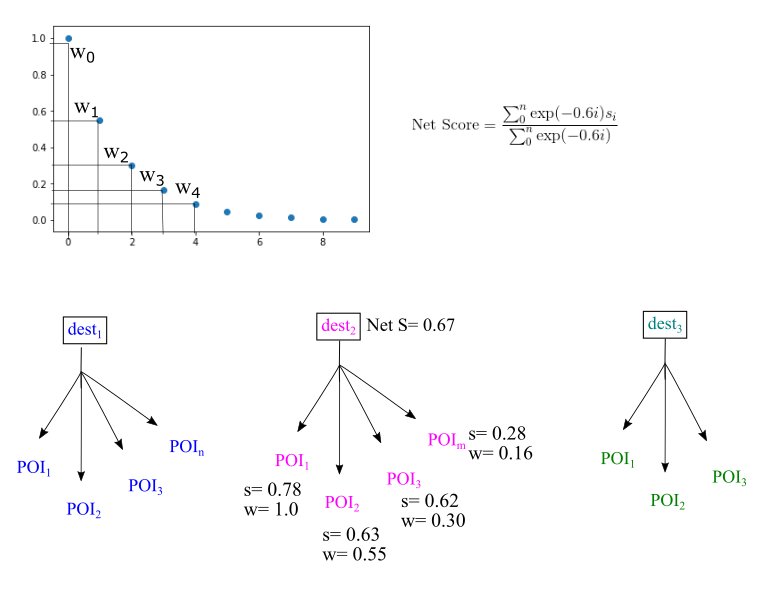
Predictions
The top 10 recommendations are shown to the user:



WikiVoyage
To compare the performance of hierarchical travel recommender system with traditional systems, I have built another content-based recommender system using the wiki-travel database. The notebooks describing the implementation can be found here.
To-do: compare bottom-up approach with one-scale approach
Collaborative filtering
- Get user profile in terms of latent variable
Model deployment and monitoring
- To-do: develop a web application and track the model performance
- To-do: adjust model parameters with user feedback (conduct a survey with web application)
Upcoming features
- User constraints e.g. a particular country
- Integration of flight and hotel information